Blog Generative Models Related
Contents
2D Generation
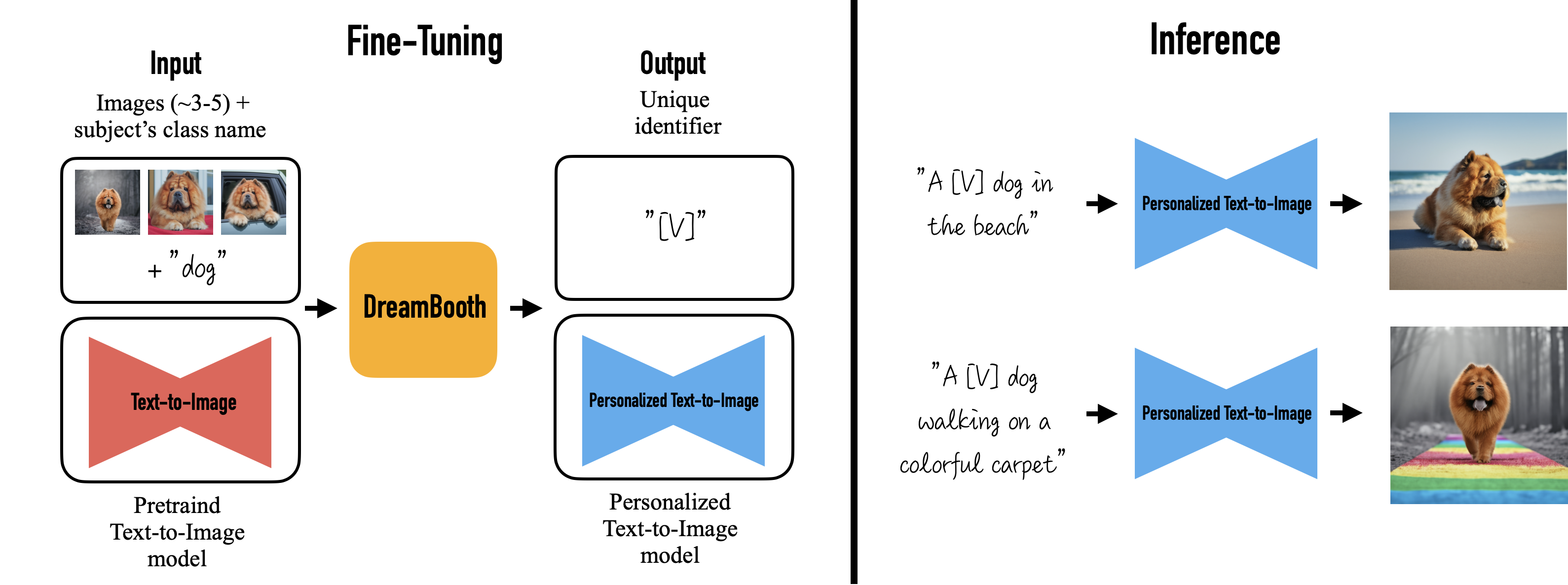
[CVPR 2023] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation [pdf][Porject]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman
- Paper writing is hard to follow.
- In this work, we present a new approach for "personalization" of text-to-image diffusion models.
Given as input just a few images of a subject, we fine-tune a pretrained text-to-image model such that it
learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output
domain of the model, the unique identifier can be used to synthesize novel photorealistic images of the
subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a
new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in
diverse scenes, poses, views and lighting conditions that do not appear in the reference images. We apply
our technique to several previously-unassailable tasks, including subject recontextualization, text-guided
view synthesis, and artistic rendering, all while preserving the subject's key features. We also provide a
new dataset and evaluation protocol for this new task of subject-driven generation.

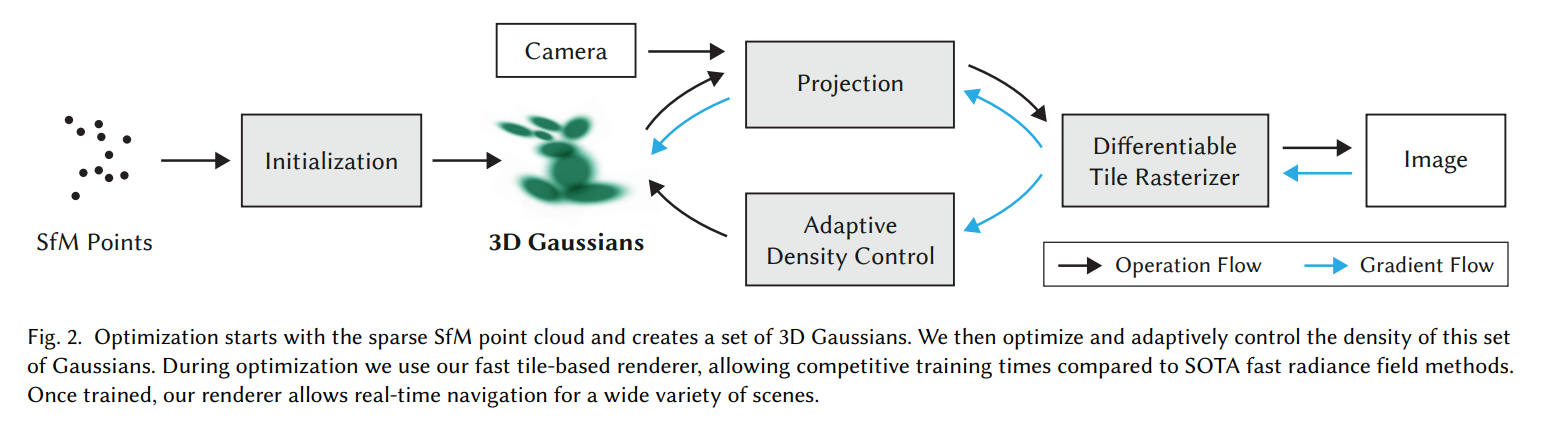
[Siggraph 2023] 3D Gaussian Splatting for Real-Time Radiance Field Rendering [pdf]
- We introduce three key elements that allow us to achieve state-of-the-art visual quality while maintaining
competitive training times and importantly allow high-quality real-time (≥ 30 fps) novel-view synthesis at
1080p resolution. First, starting from sparse points produced during camera calibration, we represent the
scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for
scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved
optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an
accurate representation of the scene; Third, we develop a fast visibility-aware rendering algorithm that
supports anisotropic splatting and both accelerates training and allows realtime rendering. We demonstrate
state-of-the-art visual quality and real-time rendering on several established datasets.
[arXiv 2024] FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model [pdf]
Qijun Feng, Zhen Xing, Zuxuan Wu, Yu-Gang Jiang
[CVM 2024] Recent Advances in 3D Gaussian Splatting [pdf]
Tong Wu, Yu-Jie Yuan, Ling-Xiao Zhang, Jie Yang, Yan-Pei Cao, Ling-Qi Yan, Lin Gao
- Gaussian Splatting for 3D Reconstruction
- Gaussian Splatting for 3D Editing
- Applications of Gaussian Splatting: Segmentation and Understanding, Geometry Reconstruction and SLAM,
Digital Human [23, 125-156]
[Google Research] StyleDrop: Text-to-Image Generation in Any Style [pdf] [blog]
Kihyuk Sohn, Nataniel Ruiz, Kimin Lee, Daniel Castro Chin, Irina Blok, Huiwen Chang, Jarred Barber, Lu Jiang,
Glenn Entis, Yuanzhen Li, Yuan Hao, Irfan Essa, Michael Rubinstein, Dilip Krishnan
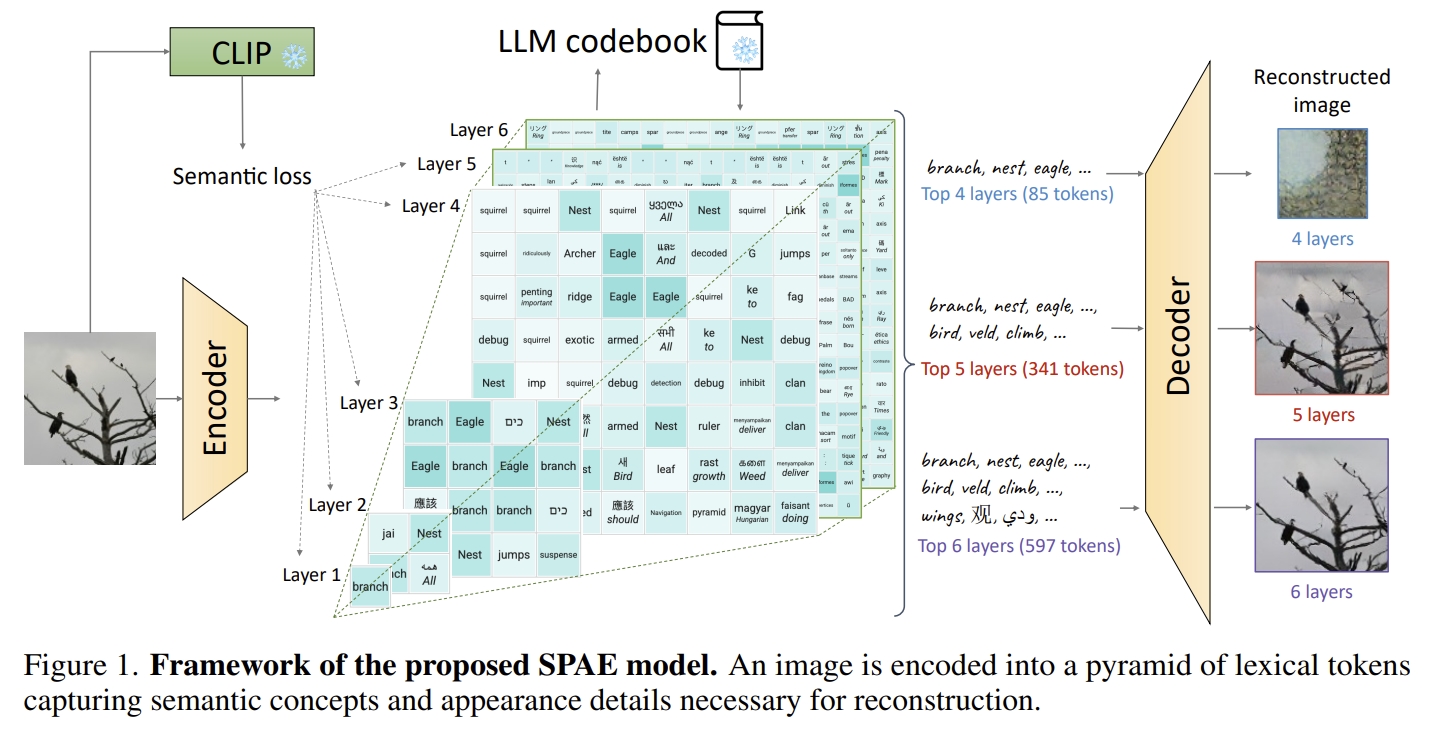
[NeurIPS 2023] SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs [pdf]
Lijun Yu, Yong Cheng, Zhiruo Wang, Vivek Kumar, Wolfgang Macherey, Yanping Huang, David A. Ross, Irfan Essa,
Yonatan Bisk, Ming-Hsuan Yang, Kevin Murphy, Alexander G. Hauptmann, Lu Jiang
- SPAE tokens have a multi-scale representation arranged in a pyramid structure. The upper layers of the
pyramid comprise semantic-central concepts, while the lower layers prioritize appearance representations
that captures the fine details for image reconstruction. This design enables us to dynamically adjust the
token length to accommodate various tasks, such as using fewer tokens for understanding tasks and more
tokens for generation tasks.
- We term this approach as Streaming Average Quantization (SAQ) due to its resemblance to computing the
average on streaming data.
- Progressive In-Context Decoding
[CVPR 2023] DynIBaR: Neural Dynamic Image-Based Rendering [pdf]
[project]
Zhengqi Li, Qianqian Wang, Forrester Cole, Richard Tucker, Noah Snavely
[arXiv 2024] Explorative Inbetweening of Time and Space [pdf]
Haiwen Feng, Zheng Ding, Zhihao Xia, Simon Niklaus, Victoria Abrevaya, Michael J. Black1, Xuaner Zhang
3D Generation
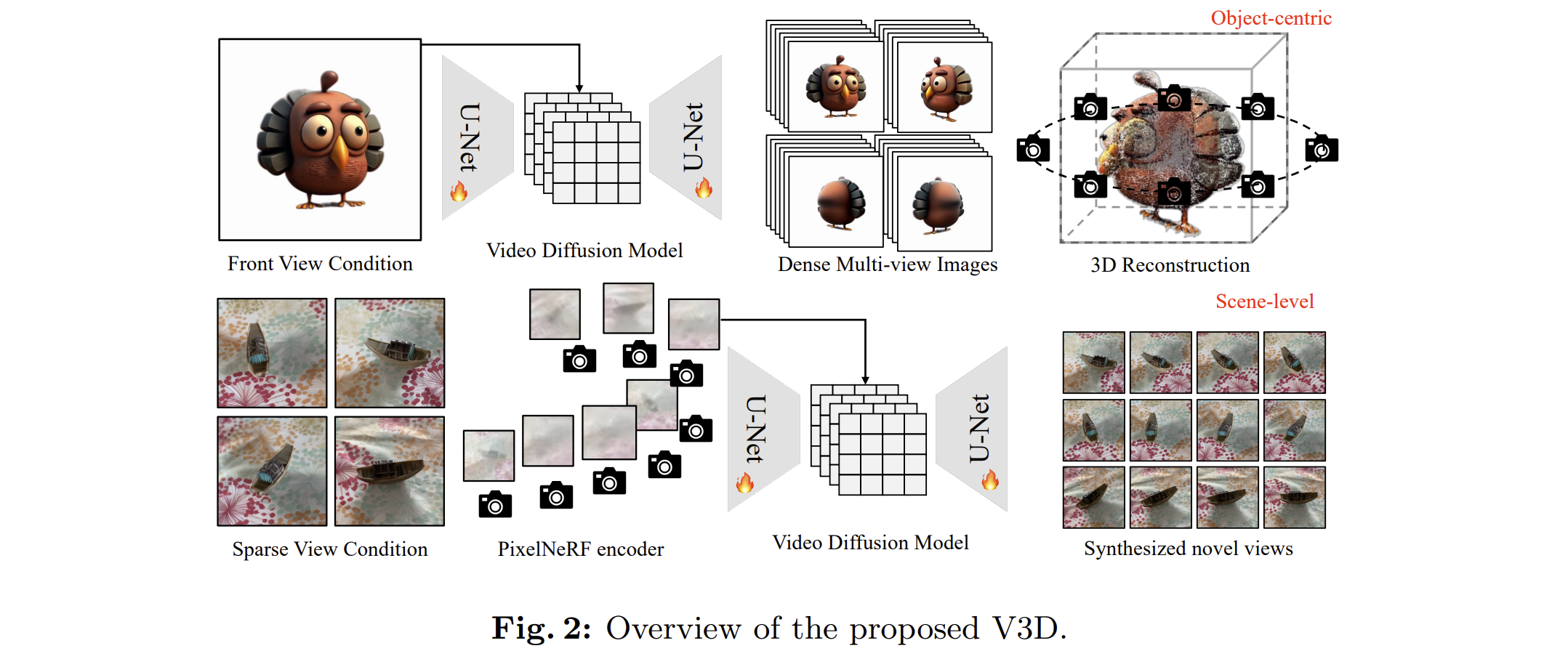
[arXiv 2024] V3D: Video Diffusion Models are Effective 3D Generators [pdf] [[code]](t
https://github.com/heheyas/V3D)
Zilong Chen, Yikai Wang, Feng Wang, Zhengyi Wang, Huaping Liu
- Motivated by recent advancements in video diffusion models, we introduce V3D, which leverages the world
simulation capacity of pre-trained video diffusion models to facilitate 3D generation. To fully unleash the
potential of video diffusion to perceive the 3D world, we further introduce geometrical consistency prior
and extend the video diffusion model to a multi-view consistent 3D generator. Benefiting from this, the
state-of-the-art video diffusion model could be fine-tuned to generate 360° orbit frames surrounding an
object given a single image. With our tailored reconstruction pipelines, we can generate high-quality meshes
or 3D Gaussians within 3 minutes. Furthermore, our method can be extended to scene-level novel view
synthesis, achieving precise control over the camera path with sparse input views. Extensive experiments
demonstrate the superior performance of the proposed approach, especially in terms of generation quality and
multi-view consistency.
[arXiv 2024] 3D-SceneDreamer: Text-Driven 3D-Consistent Scene Generation [pdf]
Frank Zhang, Yibo Zhang, Quan Zheng, Rui Ma, Wei Hua, Hujun Bao, Weiwei Xu, Changqing Zou
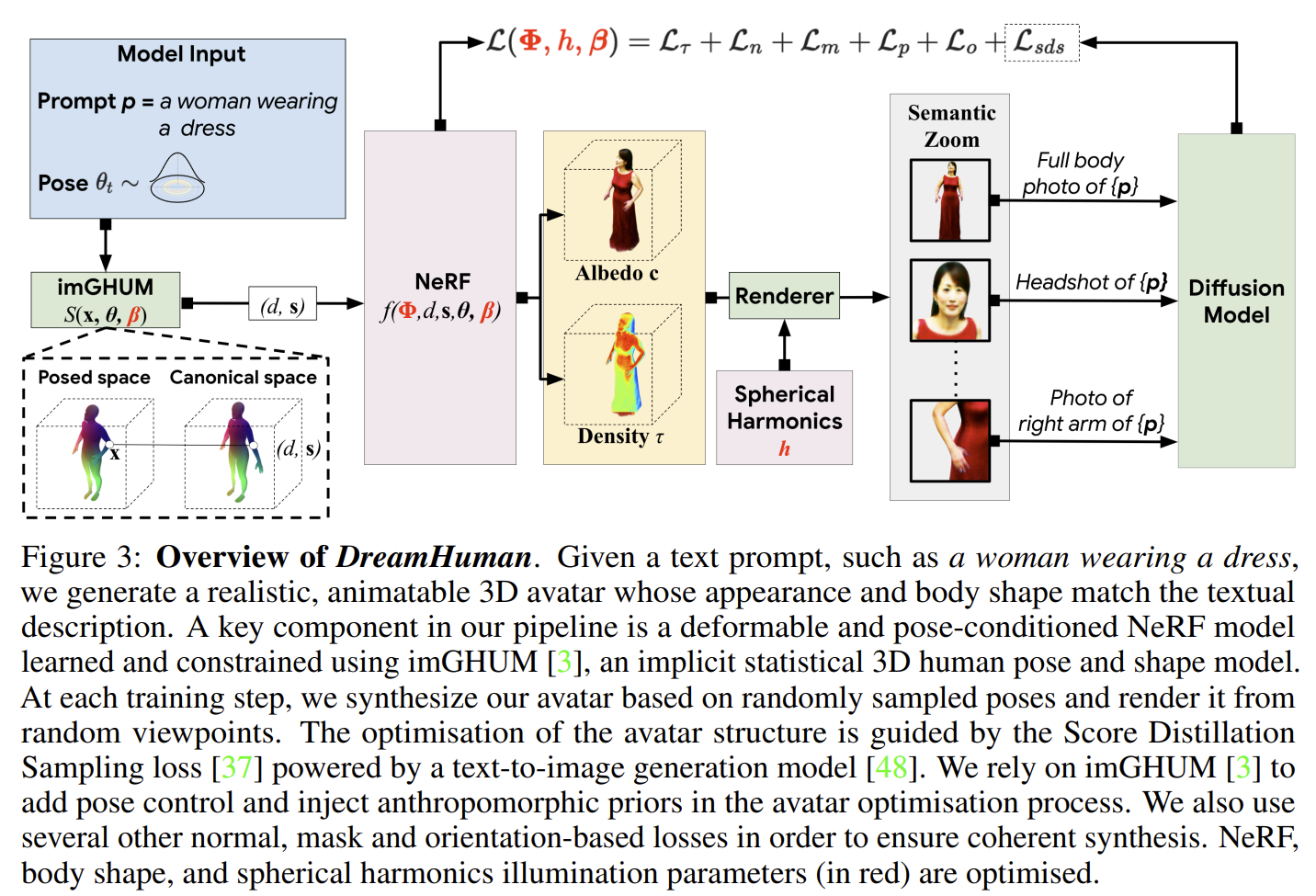
[NeurIPS 2023] DreamHuman: Animatable 3D Avatars from Text [pdf]
Nikos Kolotouros, Thiemo Alldieck, Andrei Zanfir, Eduard Gabriel Bazavan, Mihai Fieraru, Cristian
Sminchisescu
- The optimisation of the avatar structure is guided by the Score Distillation
Sampling loss powered by a text-to-image generation model.
- The optimisation of the avatar structure is guided by the Score Distillation Sampling loss powered by a
text-to-image generation model. During training, we optimise over the NeRF, body shape, and spherical
harmonics illumination parameters.
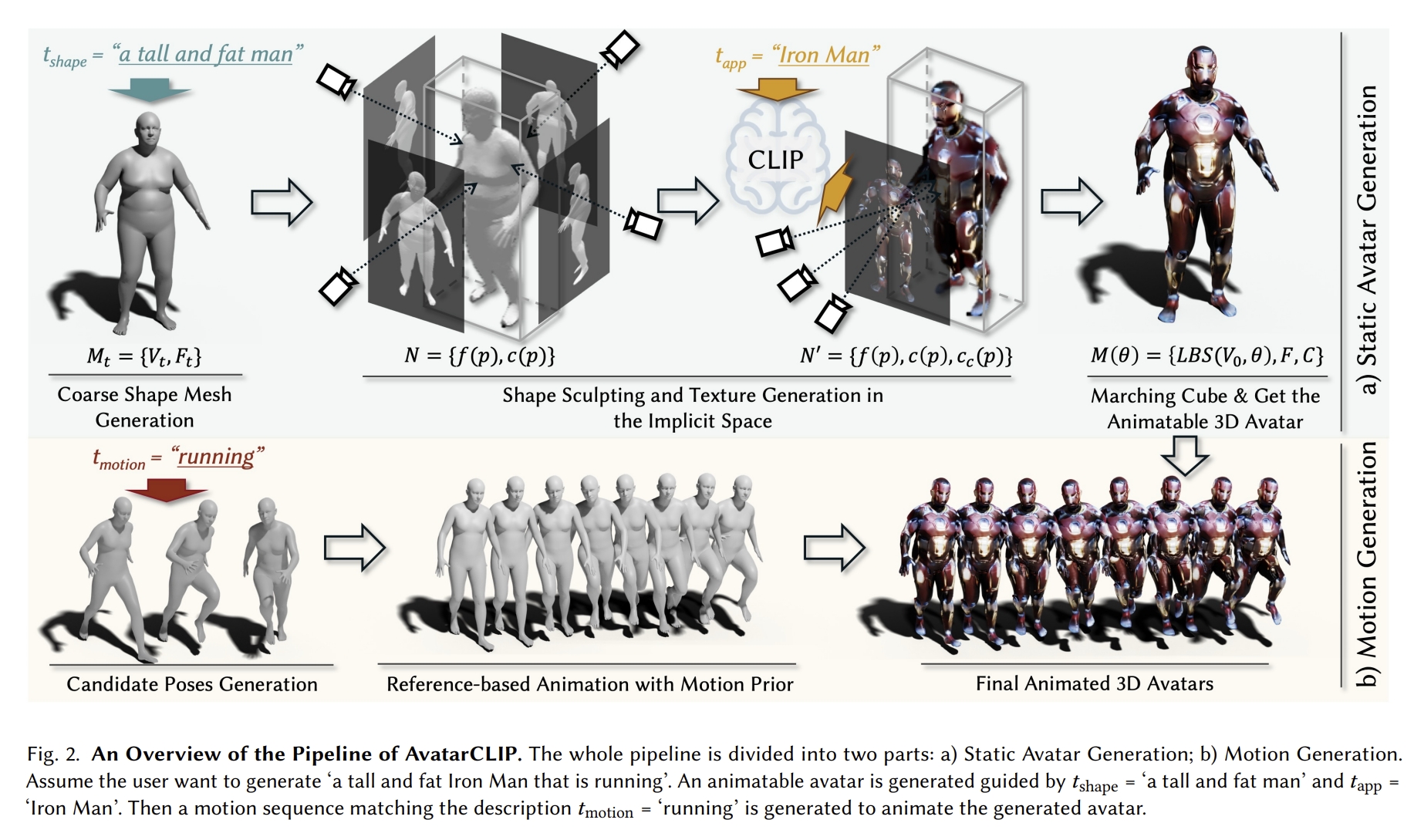
[Siggraph 2022] AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars [pdf]
Fangzhou Hong, Mingyuan Zhang, Liang Pan, Zhongang Cai, Lei Yang, Ziwei Liu
[ICCV 2023] Synthesizing Diverse Human Motions in 3D Indoor Scenes [pdf]
Kaifeng Zhao, Yan Zhang, Shaofei Wang, Thabo Beeler, Siyu Tang
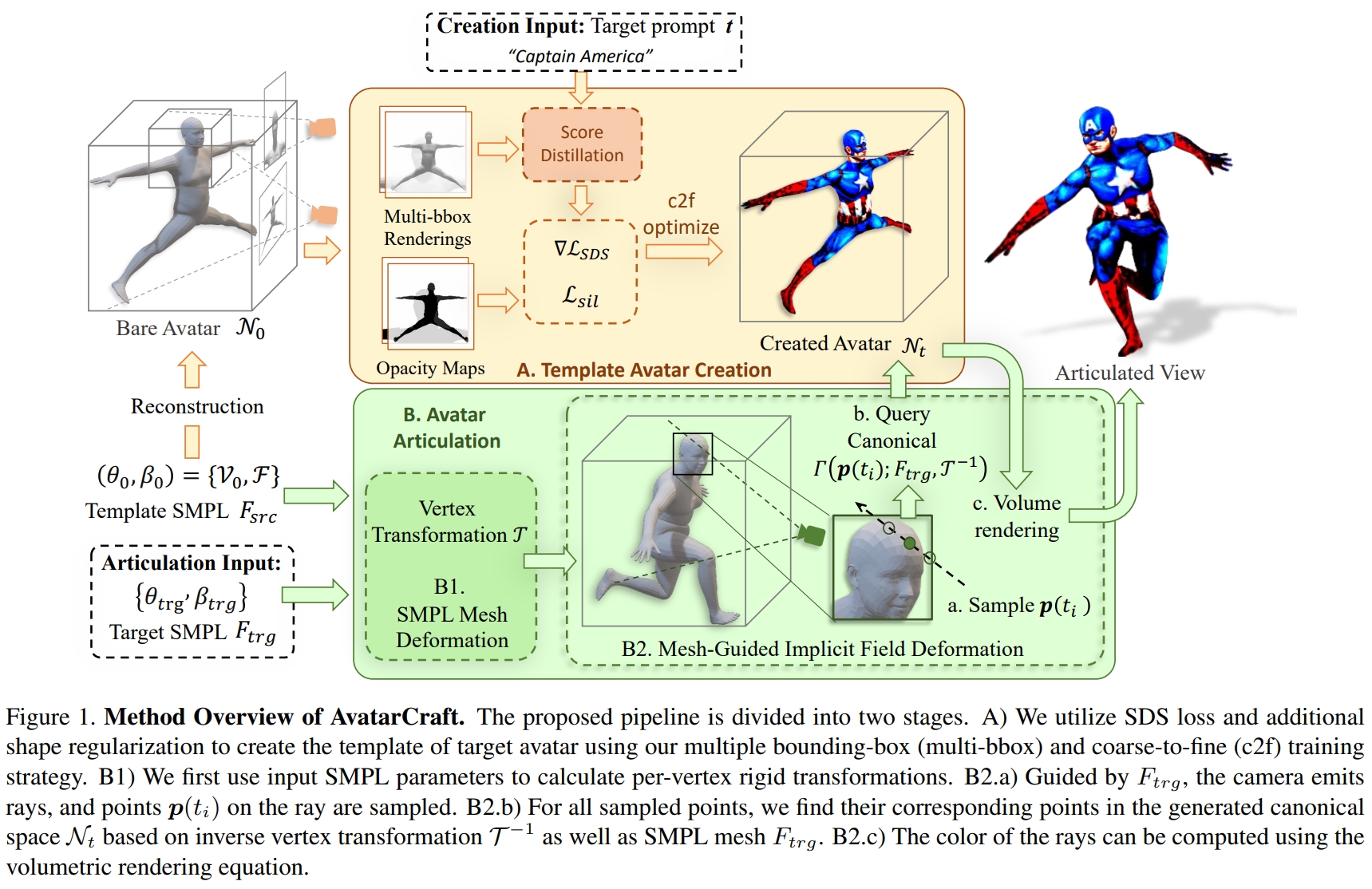
[ICCV 2023] AvatarCraft: Transforming Text into Neural Human Avatars with Parameterized Shape and Pose Control
Ruixiang Jiang, Can Wang, Jingbo Zhang, Menglei Chai, Mingming He, Dongdong Chen, Jing Liao
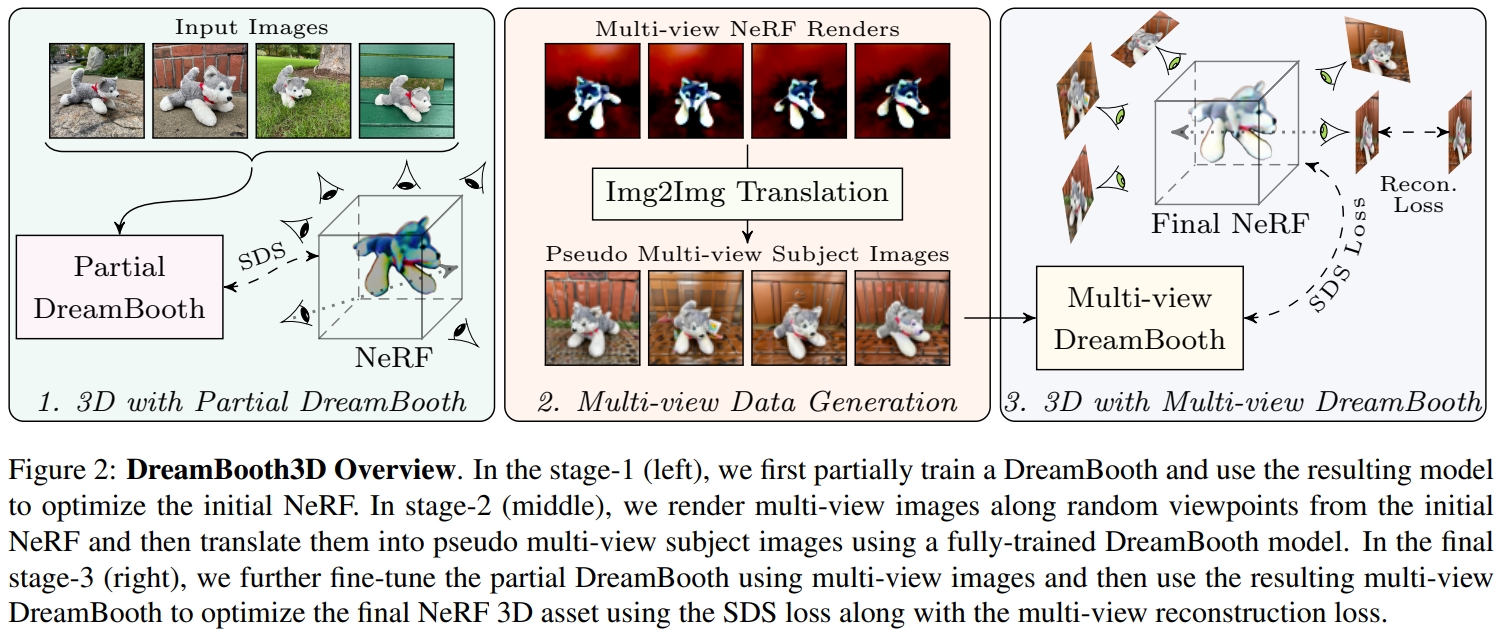
[ICCV 2023] DreamBooth3D: Subject-Driven Text-to-3D Generation [pdf]
Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Nataniel Ruiz, Ben Mildenhall, Shiran Zada, Kfir
Aberman, Michael Rubinstein, Jonathan Barron, Yuanzhen Li, Varun Jampani
- Our approach combines recent advances in personalizing text-to-image models (DreamBooth) with text-to-3D
generation (DreamFusion). We find that naively combining these methods fails to yield satisfactory
subject-specific 3D assets due to personalized text-to-image models overfitting to the input viewpoints of
the subject. We overcome this through a 3-stage optimization strategy where we jointly leverage the 3D
consistency of neural radiance fields together with the personalization capability of text-to-image models.

[arXiv 2024] Gaussian Frosting: Editable Complex Radiance Fields with Real-Time Rendering [pdf]
Antoine Guédon, Vincent Lepetit
[arXiv 2024] GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation [pdf]
Yinghao Xu, Zifan Shi, Wang Yifan, Hansheng Chen, Ceyuan Yang, Sida Peng, Yujun Shen, Gordon Wetzstein
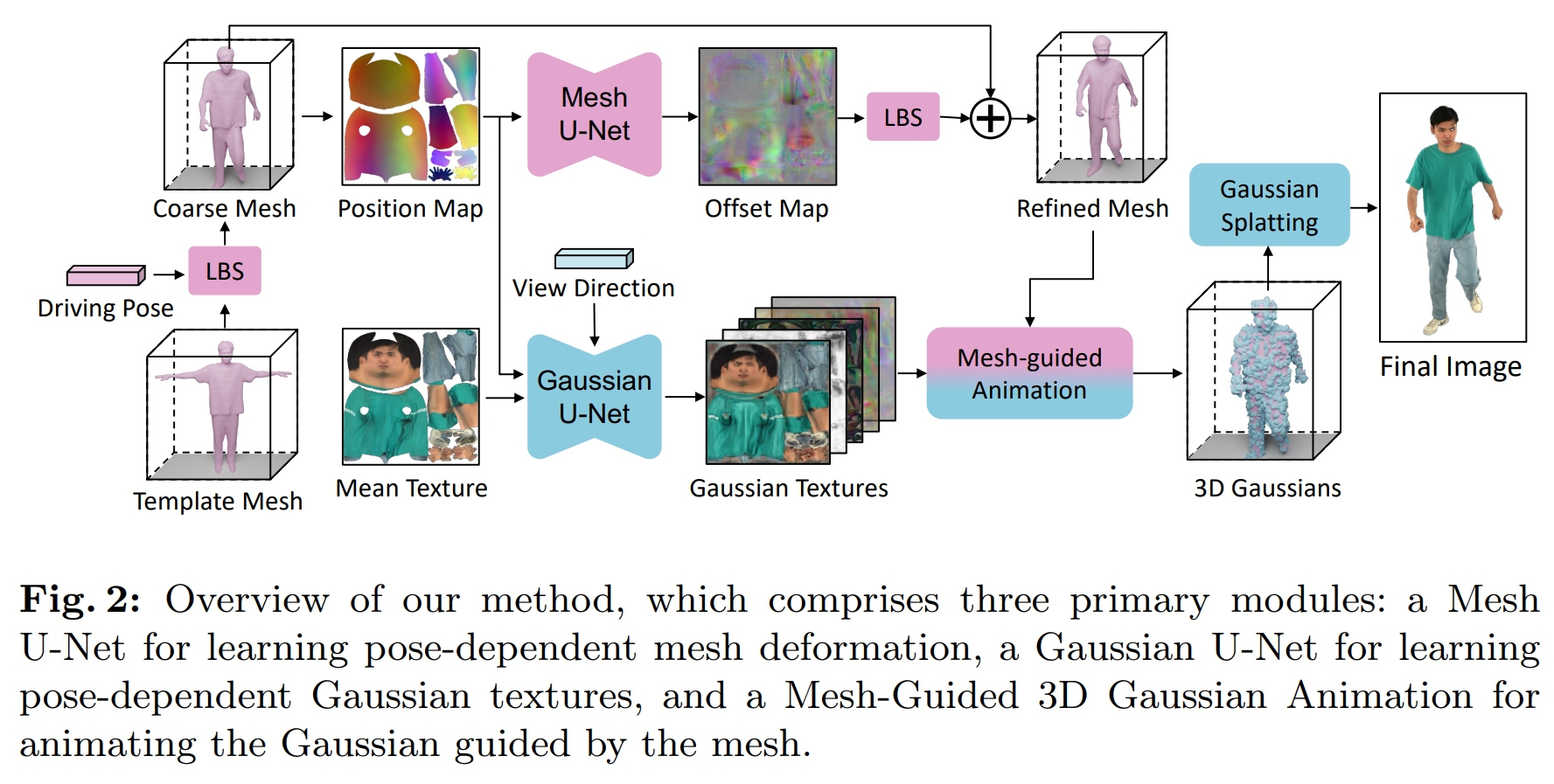
[arXiv 2024] UV Gaussians: Joint Learning of Mesh Deformation and Gaussian Textures for Human Avatar Modeling
Yujiao Jiang, Qingmin Liao, Xiaoyu Li, Li Ma, Qi Zhang, Chaopeng Zhang, Zongqing Lu, Ying Shan
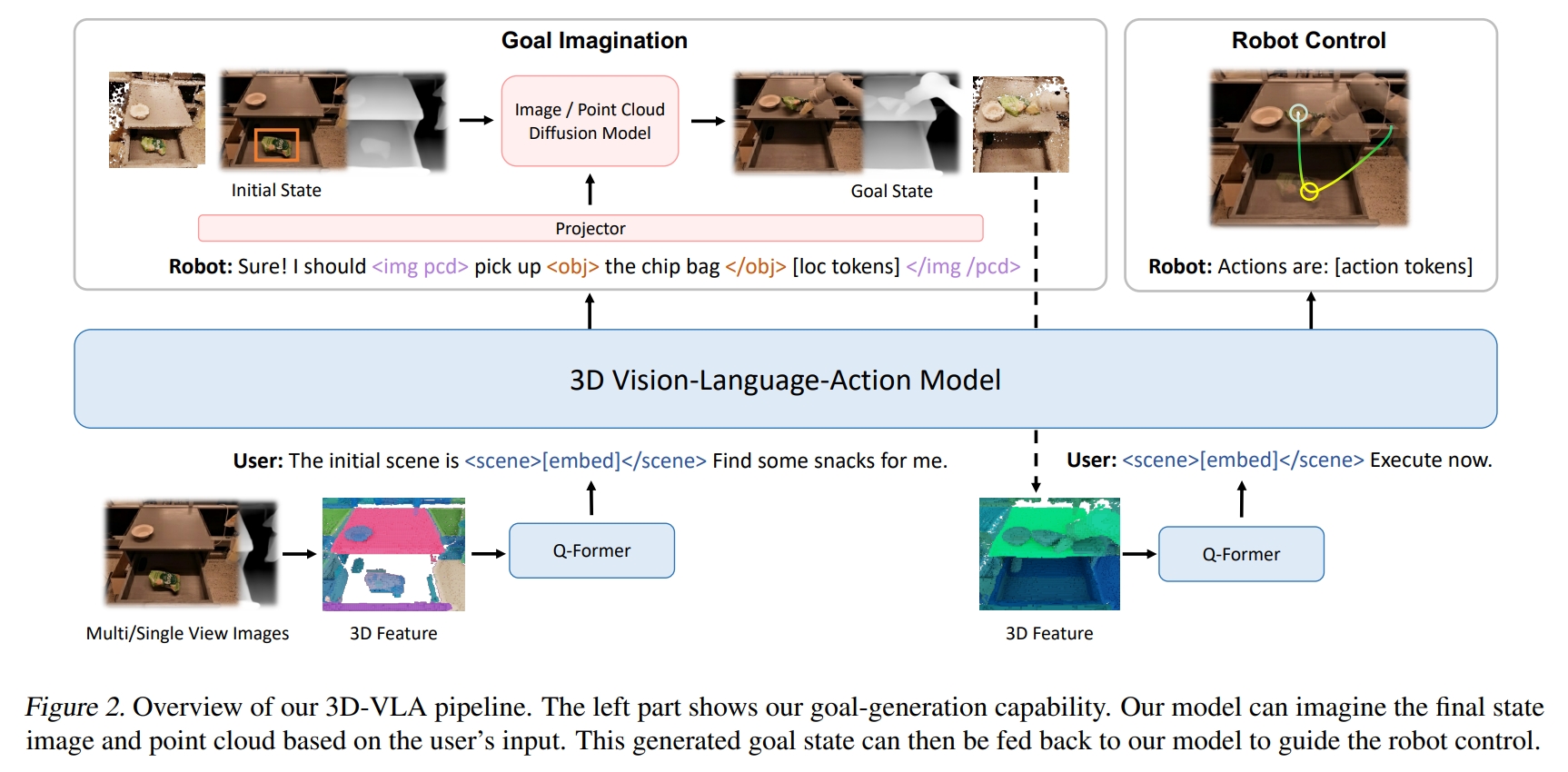
[arXiv 2024] 3D-VLA: A 3D Vision-Language-Action Generative World Model [pdf]
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, Chuang Gan
- To this end, we propose 3D-VLA by introducing a new family of embodied foundation models that seamlessly
link 3D perception, reasoning, and action through a generative world model. Specifically, 3D-VLA is built on
top of a 3D-based large language model (LLM), and a set of interaction tokens is introduced to engage with
the embodied environment. Furthermore, to inject generation abilities into the model, we train a series of
embodied diffusion models and align them into the LLM for predicting the goal images and point clouds. To
train our 3D-VLA, we curate a large-scale 3D embodied instruction dataset by extracting vast 3D-related
information from existing robotics datasets.
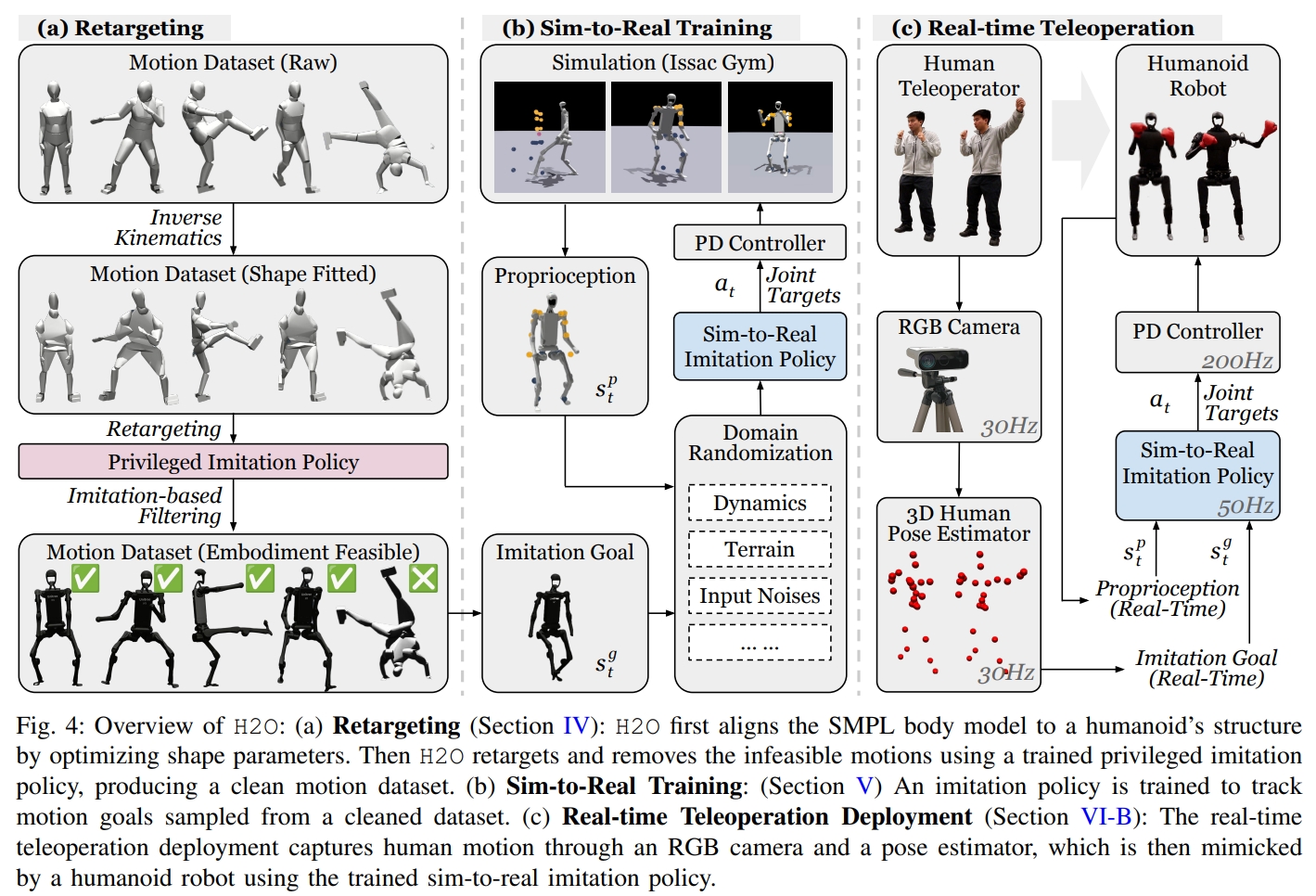
[arXiv 2024] Learning Human-to-Humanoid Real-Time Whole-Body Teleoperation [pdf]
Tairan He, Zhengyi Luo, Wenli Xiao, Chong Zhang, Kris Kitani, Changliu Liu, Guanya Shi
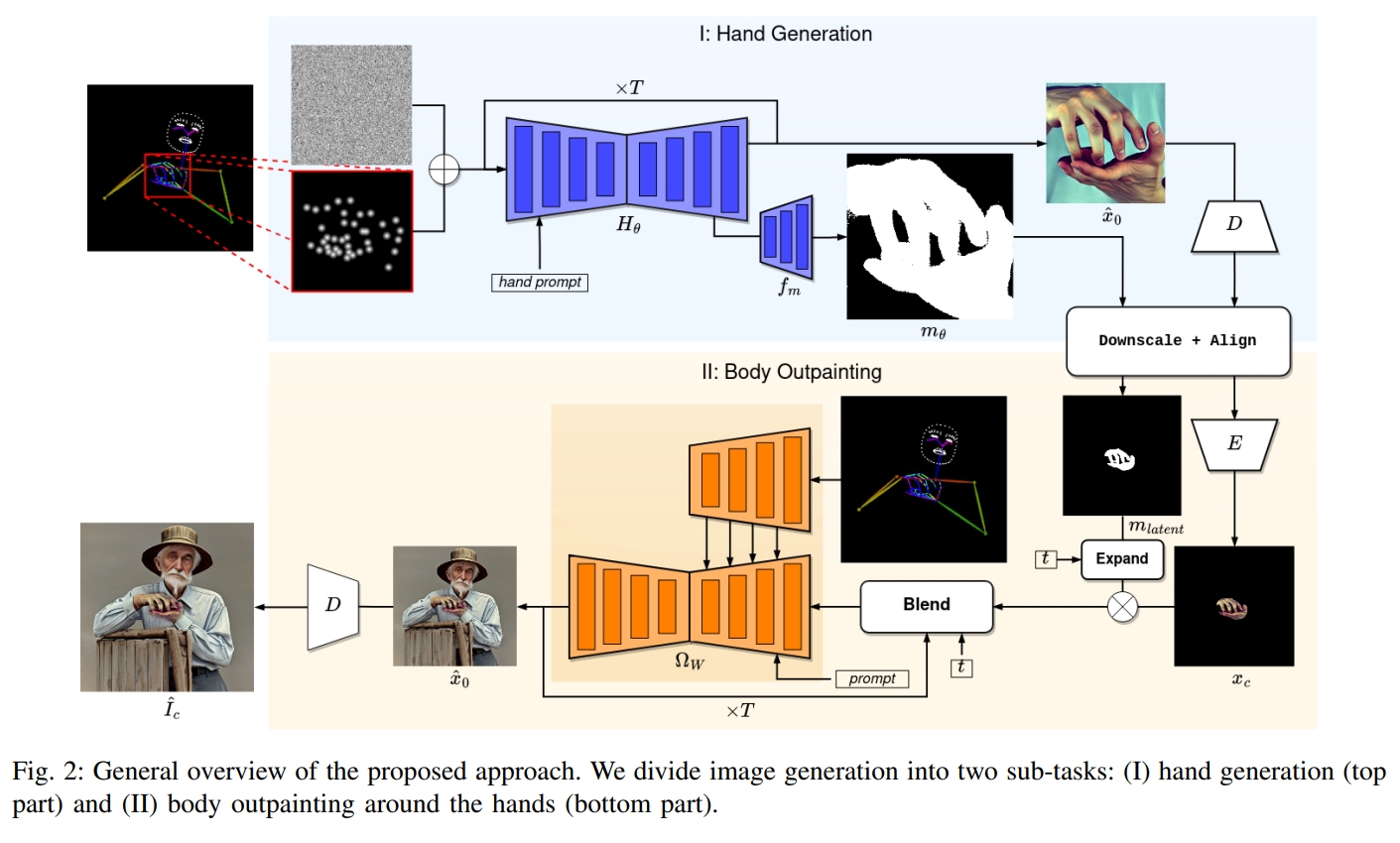
[arXiv 2024] Giving a Hand to Diffusion Models: a Two-Stage Approach to Improving Conditional Human Image
Generation
Anton Pelykh, Ozge Mercanoglu Sincan, Richard Bowden
[arXiv 2024] DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion
Models [pdf]
Zhiyao Sun, Tian Lv, Sheng Ye, Matthieu Gaetan Lin, Jenny Sheng, Yu-Hui Wen, Minjing Yu, Yong-jin Liu
Other Interesting Works
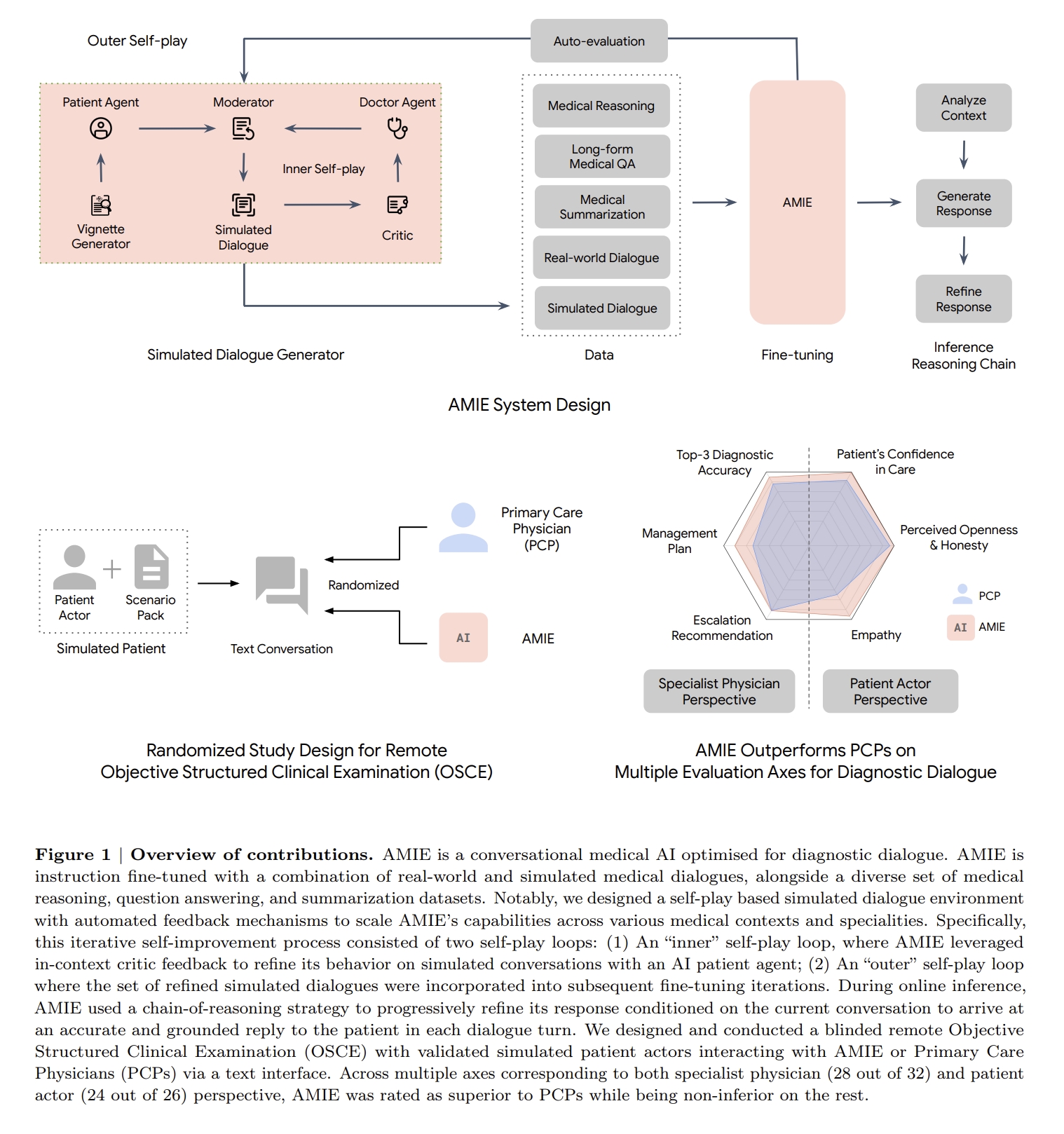
[Google Research] AMIE: A research AI system for diagnostic medical reasoning and conversations [pdf] [blog]
Tao Tu, Anil Palepu, Mike Schaekermann, Khaled Saab, Jan Freyberg, Ryutaro Tanno, Amy Wang, Brenna Li,
Mohamed Amin, Nenad Tomasev, Shekoofeh Azizi, Karan Singhal, Yong Cheng, Le Hou, Albert Webson, Kavita
Kulkarni, S Sara Mahdavi, Christopher Semturs, Juraj Gottweis, Joelle Barral, Katherine Chou, Greg S
Corrado, Yossi Matias, Alan Karthikesalingam, Vivek Natarajan
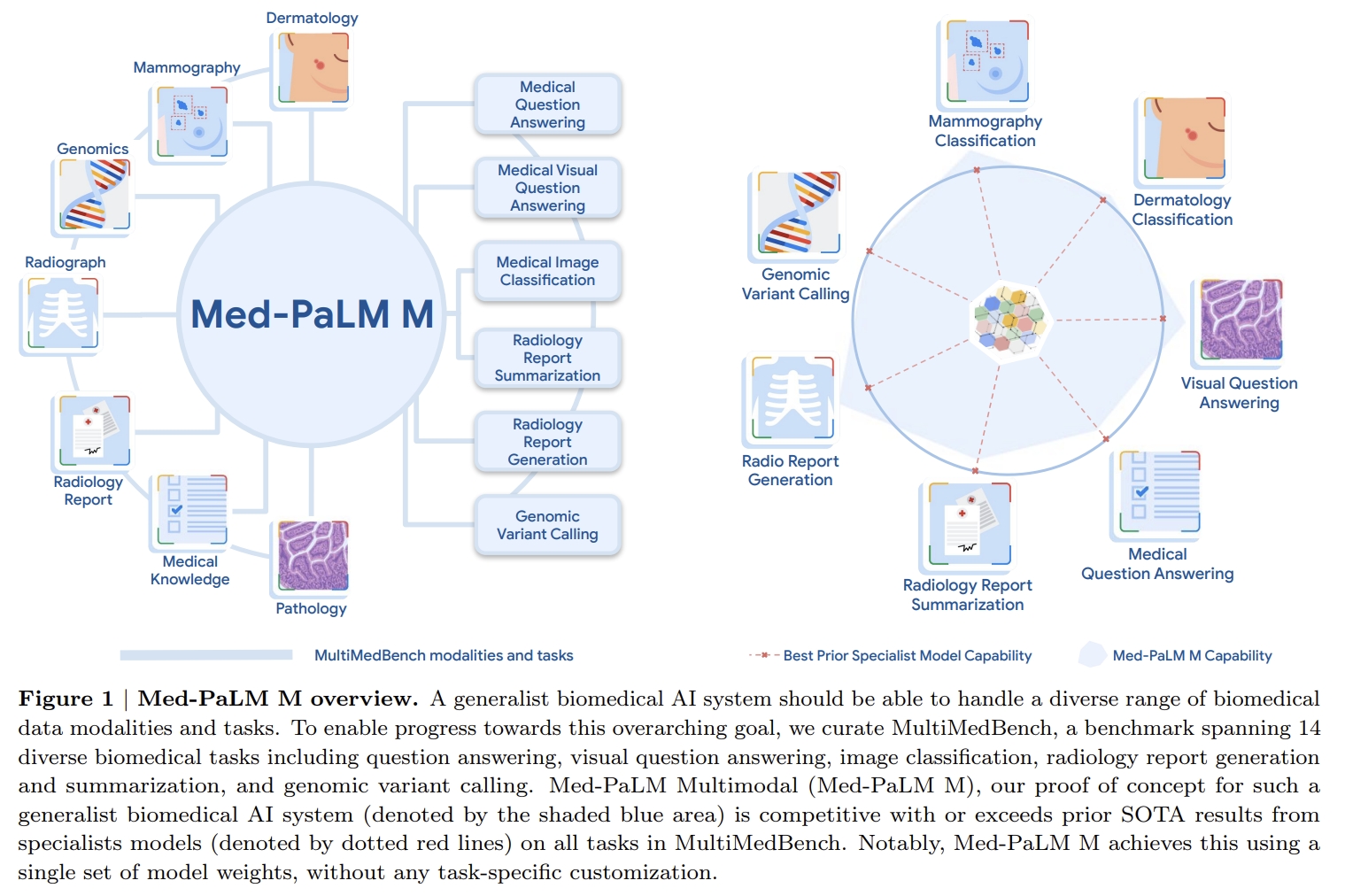
[NeurIPS 2023] Towards Generalist Biomedical AI [pdf]
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Chuck
Lau, Ryutaro Tanno, Ira Ktena, Basil Mustafa, Aakanksha Chowdhery, Yun Liu, Simon Kornblith, David Fleet,
Philip Mansfield, Sushant Prakash, Renee Wong, Sunny Virmani, Christopher Semturs, S Sara Mahdavi, Bradley
Green, Ewa Dominowska, Blaise Aguera y Arcas, Joelle Barral, Dale Webster, Greg S. Corrado, Yossi Matias,
Karan Singhal, Pete Florence, Alan Karthikesalingam, Vivek Natarajan
[Google Research] A new quantum algorithm for classical mechanics with an exponential speedup [pdf]
Robin Kothari, Rolando Somma
[ICCV 2023] SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection [pdf]
Yichen Xie, Chenfeng Xu, Marie-Julie Rakotosaona, Patrick Rim, Federico Tombari, Kurt Keutzer, Masayoshi
Tomizuka, Wei Zhan
[ICCV 2023] Audiovisual Masked Autoencoders [pdf]
Mariana-Iuliana Georgescu, Eduardo Fonseca, Radu Tudor Ionescu, Mario Lucic, Cordelia Schmid, Anurag
Arnab
EnCodec: High Fidelity Neural Audio Compression [pdf] [code]